Your AI model needs millions of data points to train effectively, but collecting real data involves privacy concerns, costs millions, and takes months. Enter synthetic data generation—the solution that’s transforming how organizations build and deploy AI systems. By 2030, Gartner predicts 60% of AI training data will be synthetically generated.
Understanding Synthetic Data
Synthetic data isn’t fake data—it’s artificially generated information that maintains the statistical properties of real datasets while protecting privacy and expanding possibilities.
Types and Categories
Synthetic data falls into three main categories:
Fully Synthetic Data
- Completely artificially generated
- No direct connection to real individuals
- Maximum privacy protection
- Examples: Simulated financial transactions, virtual patient records
Partially Synthetic Data
- Combines real and synthetic elements
- Preserves some original data relationships
- Balances utility with privacy
- Examples: Census data with modified demographics
Hybrid Synthetic Data
- Real data augmented with synthetic variations
- Enhances dataset diversity
- Maintains core authenticity
- Examples: Medical images with synthetic variations
Use Cases and Applications
Synthetic data solves real problems across industries:
✅ Training AI models when real data is scarce ✅ Testing software without production data ✅ Sharing datasets while preserving privacy ✅ Augmenting data to handle edge cases ✅ Demonstrating products without exposing sensitive information ✅ Research and development in regulated industries
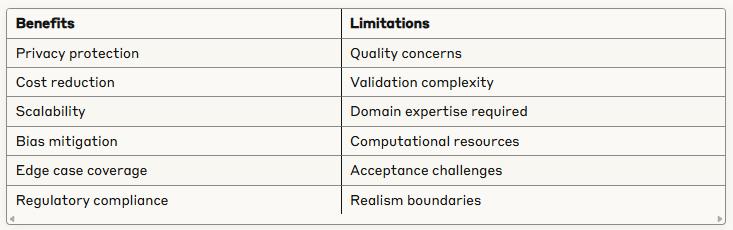
Benefits vs. Limitations
Generation Techniques
Multiple approaches create synthetic data:
Statistical Methods
Traditional techniques still prove valuable:
Monte Carlo Simulations
- Random sampling from probability distributions
- Ideal for financial modeling
- Simple implementation
- Limited complexity handling
Bayesian Networks
- Probabilistic graphical models
- Captures variable dependencies
- Excellent for structured data
- Requires domain knowledge
Bootstrapping
- Resampling with replacement
- Quick and efficient
- Limited novelty generation
- Good for small datasets
Deep Learning Approaches
Modern AI drives sophisticated generation:
Generative Adversarial Networks (GANs)
Generator → Synthetic Data → Discriminator
↑ ↓
←── Feedback Loop ────────────←- Creates highly realistic data
- Excellent for images and video
- Requires significant compute power
- Training can be unstable
Variational Autoencoders (VAEs)
- Learns data distributions
- Generates diverse outputs
- More stable than GANs
- Better for structured data
Transformer Models
- Superior for sequential data
- Handles text and time series
- Requires large training sets
- Computationally intensive
Hybrid Methodologies
Combining approaches yields best results:
✅ Statistical methods for initial structure ✅ Deep learning for refinement ✅ Rule-based systems for constraints ✅ Domain expertise for validation ✅ Iterative improvement cycles
Quality Assurance Framework
Ensuring synthetic data quality requires rigorous testing:
Fidelity Measurements
Key metrics assess synthetic data quality:
Statistical Similarity
- Distribution matching (KS test, Chi-square)
- Correlation preservation
- Summary statistics comparison
- Multivariate relationships
Utility Metrics
- Model performance comparison
- Downstream task effectiveness
- Query accuracy preservation
- Insight generation capability
Privacy Metrics
- Re-identification risk scores
- Membership inference resistance
- Attribute disclosure prevention
- Differential privacy guarantees
Validation Techniques
Systematic validation ensures reliability:
- Visual Inspection
- Distribution plots
- Correlation matrices
- Dimensionality reduction (t-SNE, PCA)
- Sample comparisons
- Statistical Testing
- Hypothesis testing
- Goodness-of-fit tests
- Time series validation
- Cross-validation scores
- Machine Learning Validation
- Train models on synthetic data
- Test on real data
- Compare performance metrics
- Evaluate generalization
Bias Detection and Mitigation
Address bias systematically:
✅ Identify protected attributes ✅ Measure representation gaps ✅ Apply fairness constraints ✅ Validate across demographics ✅ Document known limitations
Privacy and Security Benefits
Synthetic data revolutionizes data sharing:
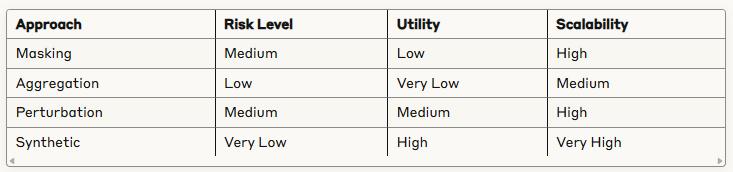
Data Anonymization
Traditional anonymization vs. synthetic generation:
Compliance Advantages
Meet regulatory requirements effortlessly:
✅ GDPR compliance – No personal data exposure ✅ HIPAA adherence – Patient privacy protected ✅ CCPA requirements – Consumer data secured ✅ Cross-border sharing – Eliminates transfer restrictions ✅ Audit trails – Clear data lineage
Risk Reduction Strategies
Minimize exposure through synthetic data:
- Zero real customer data in development
- Eliminated breach consequences
- Reduced insider threat risks
- Safe third-party sharing
- Protected intellectual property
Implementation Strategies
Deploy synthetic data generation effectively:
Tool Selection Criteria
Choose tools based on your needs:
Commercial Solutions
- Mostly.AI (tabular data specialist)
- Syntheticus (healthcare focus)
- Hazy (enterprise-grade platform)
- Gretel.ai (developer-friendly APIs)
- DataRobot (integrated ML platform)
Open-Source Options
- SDV (Synthetic Data Vault)
- CTGAN (Conditional GANs)
- DataSynthesizer
- Synthpop (R package)
- Faker (simple data generation)
Integration Approaches
Seamlessly incorporate synthetic data:
Data Pipeline Integration:
Real Data → Quality Checks → Synthetic Generation → Validation → Production Use
↓ ↓ ↓ ↓ ↓
Backup Metrics Log Model Storage Test Results MonitoringScaling Considerations
Plan for growth:
✅ Start with pilot projects ✅ Establish quality benchmarks ✅ Automate generation pipelines ✅ Implement continuous monitoring ✅ Build feedback loops
Industry Applications
Real-world success stories demonstrate value:
Healthcare and Medical Research
Synthetic data accelerates medical breakthroughs:
- Electronic Health Records: Generate millions of patient records preserving statistical relationships while protecting privacy
- Medical Imaging: Create synthetic MRI/CT scans for algorithm training
- Clinical Trials: Simulate patient populations for study design
- Drug Discovery: Generate molecular structures for testing
Case Study: Mayo Clinic generated 100,000 synthetic patient records, reducing research time by 70% while maintaining HIPAA compliance.
Financial Services
Banks and insurers leverage synthetic data:
- Fraud Detection: Create rare fraud patterns for model training
- Credit Scoring: Generate diverse credit profiles
- Trading Strategies: Simulate market conditions
- Stress Testing: Create extreme scenarios
Results: JPMorgan reduced model development time by 60% using synthetic transaction data.
Autonomous Vehicles
Self-driving cars train on synthetic scenarios:
- Edge Cases: Generate rare road conditions
- Weather Variations: Simulate diverse environments
- Pedestrian Behavior: Create unexpected movements
- Sensor Data: Generate LIDAR/camera inputs
Achievement: Waymo trains on billions of synthetic miles, covering scenarios impossible to capture safely in real world.
Retail and E-commerce
Synthetic data powers personalization:
- Customer Behavior: Generate shopping patterns
- Inventory Scenarios: Simulate demand fluctuations
- A/B Testing: Create test populations
- Recommendation Systems: Generate user preferences
Challenges and Solutions
Navigate common obstacles:
Common Pitfalls
Avoid these frequent mistakes:
❌ Over-simplification: Generating data that’s too perfect ✅ Solution: Add realistic noise and variations
❌ Ignoring relationships: Missing data dependencies ✅ Solution: Map all correlations before generation
❌ Limited validation: Insufficient quality checks ✅ Solution: Implement comprehensive testing framework
❌ Privacy overconfidence: Assuming complete anonymization ✅ Solution: Regular privacy audits and testing
Best Practices
Follow proven methodologies:
- Start Small
- Pilot with non-critical use cases
- Validate thoroughly
- Scale gradually
- Maintain Documentation
- Generation parameters
- Validation results
- Known limitations
- Use case restrictions
- Establish Governance
- Clear policies
- Regular audits
- Version control
- Access management
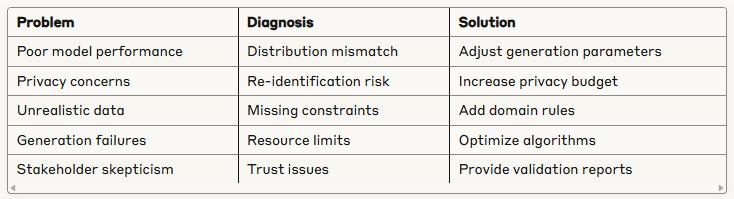
Troubleshooting Guide
Future Trends
Synthetic data generation evolves rapidly:
Emerging Technologies
Next-generation approaches:
- Quantum computing: Exponentially faster generation
- Federated synthesis: Distributed generation preserving privacy
- AutoML integration: Automated synthetic data pipelines
- Real-time generation: On-demand data creation
- Multimodal synthesis: Combined text, image, and structured data
Market Predictions
Industry growth projections:
- Market size: $1.5 billion by 2027
- Annual growth rate: 34% CAGR
- Enterprise adoption: 75% by 2030
- Cost reduction: 80% vs. real data collection
- Quality improvement: Approaching 99% fidelity
Research Directions
Academic focus areas:
✅ Differential privacy guarantees ✅ Causality preservation ✅ Cross-domain generation ✅ Explainable synthesis ✅ Adversarial robustness
Getting Started with Synthetic Data
Transform your data strategy today:
Week 1: Assessment
- Identify use cases
- Evaluate data needs
- Review privacy requirements
- Assess technical capabilities
Week 2: Pilot Planning
- Select tools
- Define success metrics
- Create validation framework
- Assign team responsibilities
Week 3: Implementation
- Generate initial datasets
- Validate quality
- Test applications
- Gather feedback
Week 4: Optimization
- Refine generation parameters
- Improve quality metrics
- Document processes
- Plan scaling
Key Takeaways
Synthetic data generation revolutionizes AI development:
- Privacy-preserving – Share data without exposing individuals
- Cost-effective – Reduce data acquisition expenses by 90%
- Scalable – Generate unlimited data on demand
- Flexible – Create edge cases impossible to collect
- Compliant – Meet regulatory requirements effortlessly
- Accelerating – Speed development cycles dramatically
- Democratizing – Enable AI development without massive datasets
The question isn’t whether to use synthetic data, but how quickly you can implement it. Organizations already leveraging synthetic data gain competitive advantages through faster development, better privacy protection, and unlimited scaling possibilities.
Start your synthetic data journey today. The tools exist, the methods are proven, and the benefits are transformative. Your AI projects don’t need to wait for perfect real data—create the data you need, when you need it, safely and efficiently.
Unlock your AI Edge — Free Content Creation Checklist
Get the exact AI-powered process to 10X your content output — blogs, emails, videos, and more — in half the time.
No fluff. No spam. Just real results with A