Making the wrong AI model choice can cost you thousands of dollars in wasted resources and months of lost development time. Yet most organizations rush into model selection without understanding the fundamental differences between options.
Let’s fix that problem.
Why Most AI Projects Fail Before They Start
AI implementation failures often trace back to a single mistake: choosing the wrong model architecture for your specific task. It’s like trying to hammer in a screw – you’re using the wrong tool for the job.
This guide will help you:
- Understand the core differences between AI model types
- Match model architectures to specific use cases
- Make cost-effective decisions based on your requirements
- Avoid common selection pitfalls
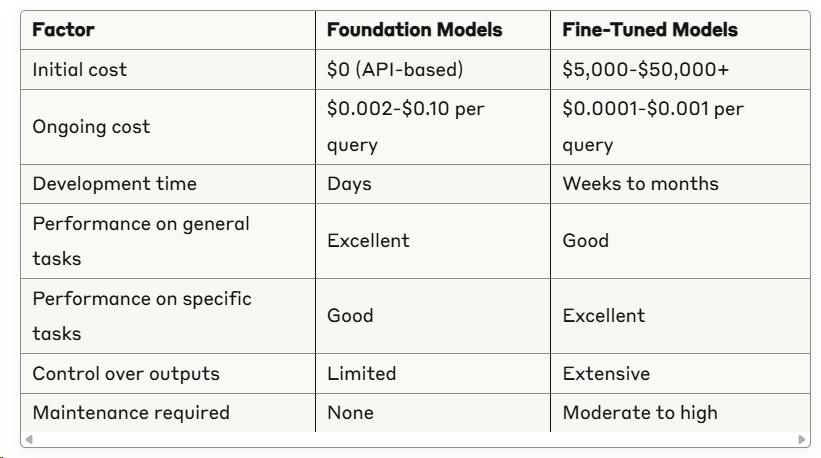
Foundation Models vs. Fine-Tuned Models
These two approaches represent a fundamental fork in the road for AI implementation.
Foundation Models
What they are: Large, general-purpose AI systems trained on vast datasets to perform a wide range of tasks.
Advantages:
- Ready to use out-of-the-box
- Capable of handling diverse tasks
- No training data required from you
- Regular updates and improvements
Disadvantages:
- Less specialized for specific tasks
- Higher per-inference costs
- Limited customization options
- Potential privacy concerns with data handling
Examples: OpenAI’s GPT-4, Anthropic’s Claude, Google’s Gemini
Fine-Tuned Models
What they are: Models that start with pre-trained weights but are further trained on specific datasets for specialized tasks.
Advantages:
- Significantly better performance on targeted tasks
- Lower inference costs after initial investment
- Greater control over outputs and behavior
- Often smaller and faster than foundation models
Disadvantages:
- Requires domain-specific training data
- Initial development costs and expertise
- Ongoing maintenance and updates needed
- Narrower application scope
Examples: Company-specific chatbots, industry-specific classifiers, custom recommendation systems
Direct Comparison
Neural Network Architectures: Choosing Your Foundation
Each neural network architecture has distinct strengths and weaknesses that make it suitable for different applications.
Transformer Models
Best for: Text generation, translation, summarization, question-answering
How they work: Use self-attention mechanisms to weigh the importance of different parts of input data.
Popular implementations:
- GPT series (generative text)
- BERT and RoBERTa (bidirectional understanding)
- T5 (text-to-text framework)
When to use: Natural language tasks where context and relationships between words matter significantly.
Convolutional Neural Networks (CNNs)
Best for: Image recognition, classification, segmentation, computer vision
How they work: Apply convolutional filters to detect features at different abstraction levels.
Popular implementations:
- ResNet and EfficientNet (image classification)
- YOLO (object detection)
- U-Net (image segmentation)
When to use: Any task involving visual data processing where spatial relationships matter.
Recurrent Neural Networks (RNNs) and LSTMs
Best for: Sequential data, time series prediction, speech recognition
How they work: Process data sequentially, maintaining an internal memory state.
Popular implementations:
- LSTM and GRU models for sequence prediction
- Bidirectional RNNs for context in both directions
When to use: Tasks with sequential dependencies, especially where earlier inputs influence later predictions.
Diffusion Models
Best for: Image generation, video creation, audio synthesis
How they work: Learn to reverse a process that gradually adds noise to data.
Popular implementations:
- Stable Diffusion
- DALL-E
- Midjourney
When to use: Creative generation tasks requiring high-quality, diverse outputs.
Multimodal Models
Best for: Tasks spanning multiple data types (text + images, audio + text)
How they work: Process and integrate information across different modalities.
Popular implementations:
- GPT-4V (text + vision)
- CLIP (images + text)
- Whisper (audio + text)
When to use: Applications requiring understanding across different types of inputs.
Learning Approaches: How Models Acquire Knowledge
The learning methodology fundamentally shapes what your model can do and how it gets there.
Supervised Learning
What it is: Models learn from labeled examples (inputs paired with correct outputs).
Best for:
- Classification tasks (spam detection, sentiment analysis)
- Regression problems (price prediction, demand forecasting)
- Object detection and recognition
Resource requirements:
- Labeled training data (often the biggest challenge)
- Clear definition of correct outputs
- Quality assurance for training data
Real-world example: A loan approval model trained on historical applications with known outcomes (approved/denied).
Unsupervised Learning
What it is: Models find patterns and structures in unlabeled data.
Best for:
- Clustering and segmentation
- Anomaly detection
- Dimensionality reduction
- Feature learning
Resource requirements:
- Large amounts of raw data
- Computational resources for processing
- Methods to validate discovered patterns
Real-world example: Customer segmentation model that identifies natural groupings in purchasing behavior.
Reinforcement Learning
What it is: Models learn optimal behavior through trial and error, receiving rewards or penalties.
Best for:
- Game playing and simulation
- Robotics and control systems
- Resource optimization
- Recommendation systems
Resource requirements:
- Well-defined reward function
- Simulation environment (typically)
- Significant computational resources
- Patience (convergence can be slow)
Real-world example: AI-powered trading system that learns investment strategies by being rewarded for profitable trades.
Model Size: Does Bigger Mean Better?
The parameter count of a model influences its capabilities, costs, and requirements.
Small Models (Under 1B Parameters)
Advantages:
- Fast inference times
- Lower computational requirements
- Can run on edge devices or consumer hardware
- Easier to deploy and maintain
Best use cases:
- Mobile applications
- IoT and edge computing
- Real-time systems with latency constraints
- Applications with limited resources
Examples: DistilBERT (66M), MobileNet (4M), TinyML models
Medium Models (1B-10B Parameters)
Advantages:
- Good balance of performance and resource usage
- Capable of handling complex tasks
- Can often run on high-end consumer hardware
- More affordable fine-tuning options
Best use cases:
- Enterprise applications
- Complex classification and generation tasks
- Specialized domain applications
- Systems with moderate resource constraints
Examples: Llama 2 (7B), GPT-J (6B), BERT-Large (340M)
Large Models (10B+ Parameters)
Advantages:
- State-of-the-art performance
- Broader knowledge and capabilities
- Better generalization to new tasks
- More reliable outputs in complex scenarios
Best use cases:
- Research and development
- Multi-task applications
- Problems requiring deep reasoning
- Applications where performance trumps cost
Examples: GPT-4 (1.76T estimated), Claude 3 Opus (1T+ estimated), PaLM (540B)
Size vs. Performance: What the Data Shows
Research indicates that while larger models generally perform better, the relationship isn’t linear:
- 10x increase in size ≠ 10x better performance
- Task-specific models often outperform general models 10-100x larger
- Domain-specific data often matters more than model size
- Small models with recent architectural improvements often outperform older, larger models
Specialized vs. General-Purpose Models
The degree of specialization is another critical decision point.
General-Purpose Models
Advantages:
- Versatility across multiple tasks
- Easier to adapt to new requirements
- Broader knowledge base
- Usually more regularly updated
Disadvantages:
- Jack of all trades, master of none
- Higher computational requirements
- Potentially more expensive at scale
- May include unnecessary capabilities
When to choose: Early-stage development, multiple use cases, uncertain requirements, rapid prototyping
Specialized Models
Advantages:
- Superior performance on targeted tasks
- Lower resource requirements
- Better efficiency and speed
- Often more accurate for domain-specific applications
Disadvantages:
- Limited application beyond core function
- Requires domain expertise to evaluate
- May become outdated as general models improve
- Potentially more maintenance overhead
When to choose: Well-defined use case, performance-critical applications, resource-constrained environments, domain-specific requirements
Open Source vs. Proprietary Models
Your choice between open and closed models affects more than just cost.
Open Source Models
Advantages:
- Transparency and auditability
- Full control over deployment
- No vendor lock-in
- Community support and improvements
- Lower long-term costs
Disadvantages:
- Higher initial implementation effort
- Responsibility for security and updates
- May require significant infrastructure
- Often less user-friendly documentation
Notable examples: Llama 2, Mixtral, Stable Diffusion, BERT
Proprietary/API Models
Advantages:
- Easier implementation via APIs
- Regular updates and improvements
- Reduced maintenance burden
- Often better documentation and support
- Scalable infrastructure handled for you
Disadvantages:
- Ongoing usage costs
- Limited control and customization
- Potential privacy and data concerns
- Dependency on provider’s business continuity
Notable examples: GPT-4, Claude, Gemini, DALL-E
Cost Comparison Example
Task: Building a customer service AI to handle 100,000 queries monthly
Open Source Approach:
- Initial setup: $10,000-$50,000 (infrastructure, engineering)
- Monthly infrastructure: $500-$5,000
- Maintenance: $2,000-$10,000 monthly (part-time engineer)
- First-year total: $34,000-$180,000
API Approach:
- Initial integration: $2,000-$10,000
- Monthly API costs: $2,000-$10,000 (at $0.02-$0.10 per query)
- Maintenance: $500-$2,000 monthly
- First-year total: $32,000-$156,000
Break-even analysis: Open source approaches often become more economical after 12-24 months, depending on query volume and complexity.
Decision Framework: Choosing the Right Model
Follow this structured approach to select the optimal model for your needs:
Step 1: Define Your Requirements
Answer these questions:
- What specific problem are you solving?
- What type of data will the model process?
- What’s your accuracy requirement?
- What are your latency constraints?
- What’s your budget (both initial and ongoing)?
- Do you have domain-specific data available?
Step 2: Evaluate Your Resources
Take inventory of:
- Available computational resources
- Internal AI/ML expertise
- Data collection and preprocessing capabilities
- Deployment environment constraints
- Regulatory and compliance requirements
Step 3: Prioritize Your Constraints
Rank these factors by importance:
- Performance/accuracy
- Cost (initial vs. ongoing)
- Development time
- Customization needs
- Privacy requirements
- Explainability needs
Step 4: Match to Model Types
Based on your priorities:
- Performance-critical + specific domain → Fine-tuned specialized model
- Rapid deployment + diverse tasks → Foundation model API
- Budget-conscious + long-term project → Open source model
- Edge deployment + real-time needs → Small specialized model
Step 5: Prototype and Test
Before full implementation:
- Test multiple approaches with sample data
- Measure performance against your specific metrics
- Calculate total cost of ownership for top candidates
- Evaluate scalability as usage grows
Real-World Selection Examples
Case 1: E-commerce Product Recommendation
Requirements:
- Personalized recommendations based on user behavior
- Integration with existing product database
- Cost efficiency at scale (millions of recommendations)
Best choice: Fine-tuned collaborative filtering model Why: High volume of predictions makes API costs prohibitive, while existing user-product interaction data enables effective model training.
Case 2: Legal Document Analysis
Requirements:
- Extract key clauses and obligations from contracts
- Understand complex legal language
- High accuracy and reliability
Best choice: Foundation model API with prompt engineering Why: Legal expertise is hard to encode, while large foundation models have strong language understanding capabilities that can be directed through effective prompting.
Case 3: Manufacturing Quality Control
Requirements:
- Real-time defect detection from camera feeds
- Integration with existing production line
- Consistent operation in controlled environment
Best choice: Specialized CNN deployed on edge hardware Why: Specific, unchanging task with real-time requirements makes a small, specialized vision model ideal.
Final Thoughts: Beyond the Technical Specs
While technical considerations are important, don’t overlook these factors:
- Team expertise – Choose models your team can effectively implement and maintain
- Future adaptability – Consider how your needs might evolve over time
- Total cost of ownership – Factor in all costs, not just the model itself
- Implementation timeframe – Balance perfect solutions against time-to-market
- Explainability requirements – Consider regulatory and trust implications
The best AI model isn’t always the most advanced or the most popular—it’s the one that solves your specific problem within your constraints.
Start with a clear understanding of your needs, test multiple approaches when possible, and remember that model selection is just one part of successful AI implementation.
Unlock your AI Edge — Free Content Creation Checklist
Get the exact AI-powered process to 10X your content output — blogs, emails, videos, and more — in half the time.
No fluff. No spam. Just real results with Ai.